Problem
Auf einem Server können keine neuen Volumenschattenkopie-Jobs angelegt werden („Das Volumen ist bereits vorhanden“), es können keine weiteren Schattenkopien für ein DPM-geschütztes Voume angelegt werden („Die Schattenkopie mit der ID xxxxxxxxxxxxx ist bereits vorhanden“) und/oder bestehende DPM-Jobs starten nach einem Volumenwechsel nicht mehr, weil die bestehenden Jobs auf das „alte“ Volumen zeigen („Es wurde bereits eine Schattenkopie mit der ID xxxxxxxxxxx gefunden“).
Lösung
Zuerst sind die bestehnden verwaisten Schattenkopien zu entfernen, dann das Ziel-Volumen (Shadowcopy-Storage). Es gibt mehrere Möglichkeiten die Einträge der Schattenkopie-Liste eines Systems aufzuräumen.
1) Sofern die orginal-Volumenzuordnung noch existiert, ist es möglich aud der Liste der Schattenkopien die ID der betroffenen Kopie zu extrahieren:
vssadmin list shadows
Aus der ausgegebenen Liste nun einfach die Schattenkopie-ID kopieren und löschen:
vssadmin Delete Shadows /shadow={Schattenkopie-ID}
Zum Beispiel: vssadmin Delete Shadows /shadow={affeaffe-dead-beef-b444-dfafafafafdf}
2) Wenn Vssadmin dabei aber seltsame Fehler ausspuckt, hat die Zuordnung nicht (mehr) richtig funktioniert. Hier hilft es in der Regel, die betroffene Kopie direkt zu entfernen; dazu gibt es ein WMI-Interface für den VSS-WMI-Provider.
C:\>wmic
wmic:root\cli>shadowcopy list
Zeigt die vorhandene Liste an. Einzelne einträge kann man löschen. pro Eintrag erfolgt eine einzelne Abfrage:
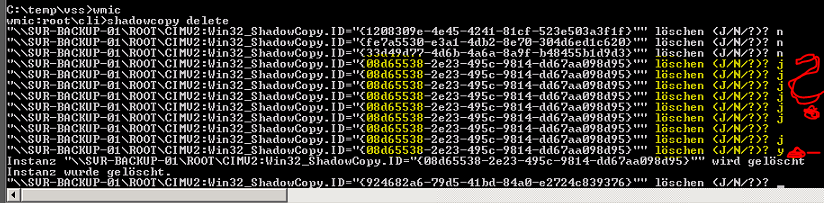
C:\>wmic
wmic:root\cli>shadowcopy delete
"\\SERERNAME\ROOT\CIMV2:Win32_ShadowCopy.ID="{Schattenkopie-ID}" löschen (J/N/?)?
ACHTUNG! Obwohl Das Tool nach J/N fragt, wird ein „Y“ zum bestätigen benötigt *seufz*.
 Wenn ein ganzes Volumen verwaist ist, zum Beisspiel wenn ein Admin darauf geschützte oder vom DPM als Ziel verwendete Partitionen entfernt, ist uns keine andere Möglichkeit bekannt, als dem Volumen eine neue Seriennummer zu geben. Das geht indem man das betroffene physikalische Array einfach löscht und neu erstellt, oder die Seriennummer einer neu erstellten NTFS-Partition mit „Volume-ID“ aus der Sysinternals-Trickkiste verändert:
Wenn ein ganzes Volumen verwaist ist, zum Beisspiel wenn ein Admin darauf geschützte oder vom DPM als Ziel verwendete Partitionen entfernt, ist uns keine andere Möglichkeit bekannt, als dem Volumen eine neue Seriennummer zu geben. Das geht indem man das betroffene physikalische Array einfach löscht und neu erstellt, oder die Seriennummer einer neu erstellten NTFS-Partition mit „Volume-ID“ aus der Sysinternals-Trickkiste verändert:
C:\>volumeid T: f0000-ba00
ACHTUNG: Danach die Maschine neu starten und NICHT VERSUCHEN eine Schattenkpie anzulegen. Nach dem Neustart sollte das Volumen aus der VSS-Zielliste verschwunden sein. Das ist zu prüfen mit:
C:\>vssadmin list shadowstorage