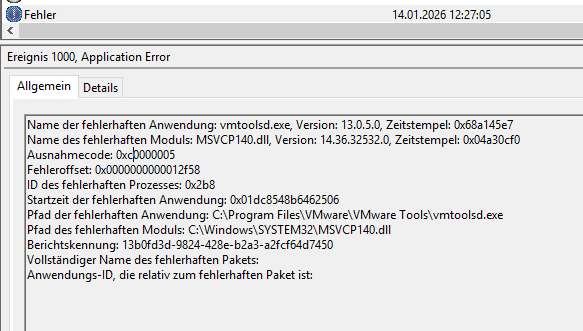
Nach dem Upgrade der VMware Tools auf Version 13 (0.1.0+) startet der „VMware Tools“ Dienst auf virtuellen Maschinen (VMs) unter Windows Server 2019 nicht mehr. Versucht man das manuell, sieht man im Anwendungs-Ereignisprotokoll die Meldung:
Name der fehlerhaften Anwendung: vmtoolsd.exe, Version: 13.0.5.0,
Name des fehlerhaften Moduls: MSVCP140.dll, Version: 14.36.32532.0,
Ausnahmecode: 0xc0000005
Fehleroffset: 0x0000000000012f58
ID des fehlerhaften Prozesses: 0x2b8
Pfad der fehlerhaften Anwendung: C:\Program Files\VMware\VMware Tools\vmtoolsd.exe
Pfad des fehlerhaften Moduls: C:\Windows\SYSTEM32\MSVCP140.dll
Vollständiger Name des fehlerhaften Pakets:
Anwendungs-ID, die relativ zum fehlerhaften Paket ist:
Lösung
Die jeweils aktuelle Microsoft Visual C++ Redistributable (14) installieren und neu starten.
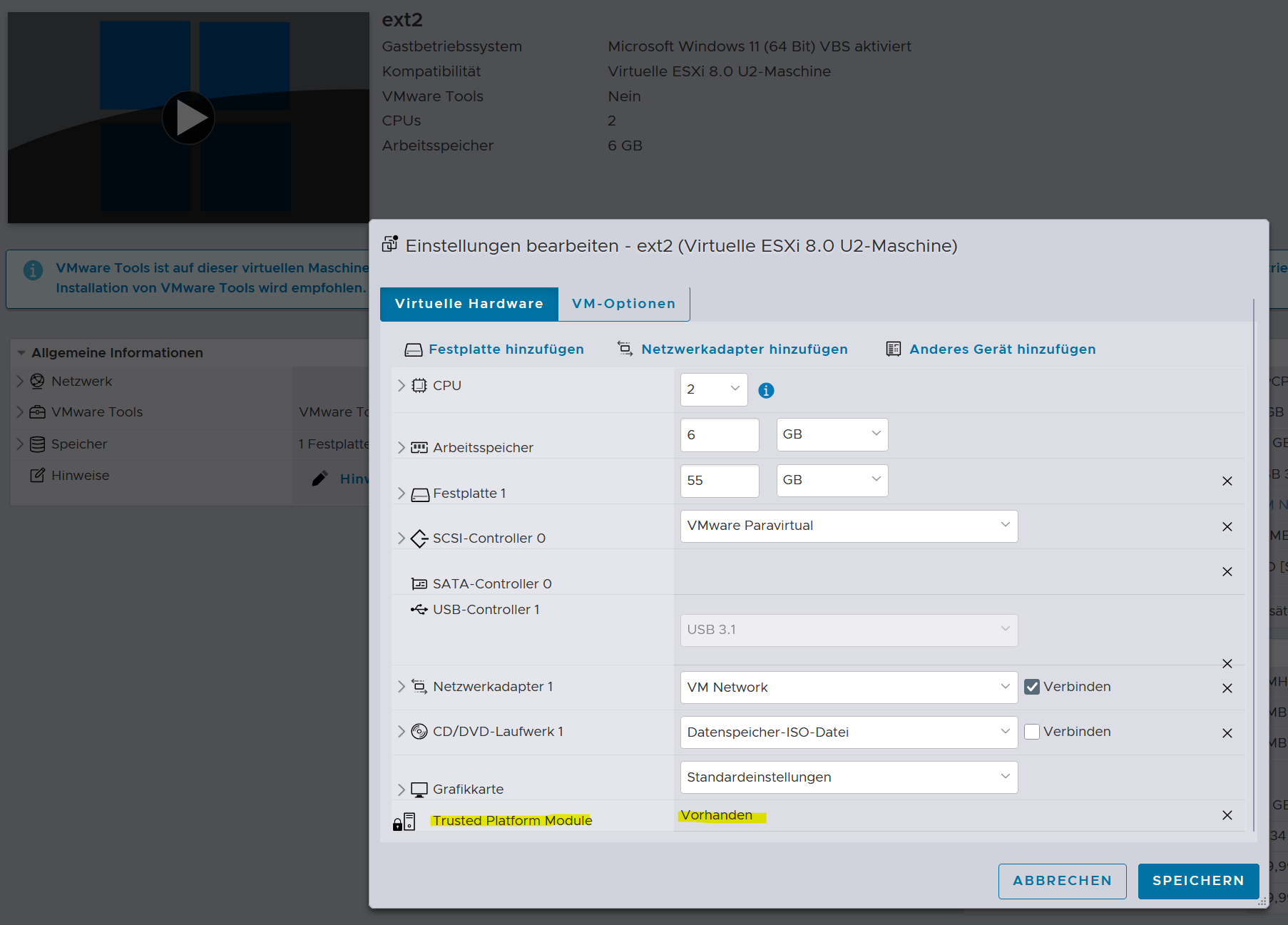
Bereits ab vSphere 6.7 kann man ein virtuelles Trusted Platform Module (vTPM) zu VM Gästen hinzufügen. Damit können Gastbetriebssysteme ihre privaten Schlüssel in einem „physischen“ (meint: VM-Hardware) TPM 2.0-Chips erstellen und speichern. Für den Gast ist das vollständig transparent, dieser kann nicht feststellen das er nicht mit einem „echten“ TPM spricht.
Der wesentliche Vorteil von vTPM ist, dass im ESXi-Host kein physischer TPM-Chip eingebaut sein muss. Server-TPMs sind ja auch nicht gerade günstig. Die Secrets aus dem vTPM wiederum werden (verschlüsselt) in der .nvram Datei des ESXi zu jeder VM einzeln und lokal abgelegt.
Die Verschlüsselungsschlüssel für das vTPM selbst wird von einem „Schlüsselanbieter“ verwaltet. Das kann ein externer (KMIP) Key Provider (SKP) oder der im vCenter integrierte Native Key Provider (NKP) sein. Die (zentrale) Verwaltung der Schlüsselanbieter erfordert aber eigentlich immer den Einsatz des vCenters. Windows 11 auf einem ESX-Standalone Host als Gast zu betreiben ist also eigentlich nicht möglich.
Interessanterweise nutzt das vCenter zur Verwaltung nur public vSphere-APIs, die auf ESXi-Hosts verfügbar sind um Schlüssel hinzuzufügen oder zu entfernen. Die Funktionen zur Verwaltung der Schlüssel ist aber ESXi Bestandteil. Das bedeutet, man kann das auch manuell machen: nicht so komfortabel wie ein vCenter Server, aber trotzdem vTPM für VMs auf eigenständigen (Standalone) ESXi-Hosts.
vSphere Master Willian Liam hat dazu einen fantastischen Artikel geschrieben und ein PowerShell-Script erstellt, das einem den Großteil der Arbeit abnimmt.
vTPM auf einem ESXi Host aktivieren, ohne Neustart
⚠️ Wichtig: Nach dieser Prozedur starten VMs nach einem ESX Reboot nicht mehr. Man muss sich um die Schlüsselpersistenz der TPM-Keys selbst kümmern (siehe weiter unten).
vmWare PowerCli Module installieren und importieren, sofern noch nicht geschehen: Install-Module VMware.PowerCLI Import-Module VMware.PowerCLI
PowerCLI mit dem ESXi-Host verbinden: Connect-VIServer -Server ESX.EXAMPLE.COM
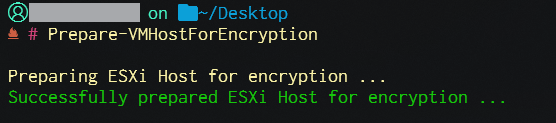
Den TPM-Provider einrichten, also den lokalen Host für den Anbieter vorbereiten: Prepare-VMHostForEncryption
Einen ESXi Hostschlüssel erzeugen: New-InitialVMHostKey -Operation CREATE -KeyName "esx10-key-1" ⚠️ Diesen Vorgang nur ein einziges Mal durchführen!
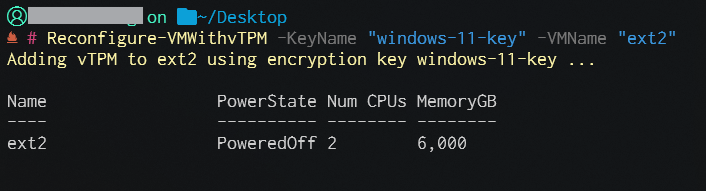
vTPM Schlüssel für VMs erstellen: New-VMTPMKey -Operation CREATE -KeyName "windows-11-key"
Und endlich kann man das vTPM zu den VMs (jeweils einzeln) hinzufügen: Reconfigure-VMWithvTPM -KeyName "windows-11-key" -VMName "EXAMPLE-VM"
⚠️ Schlüsselpersistenz – Schlüssel nach (ESX-) reboots wiederherstellen
Standardmäßig speichert ESXi leider keine Verschlüsselungsschlüssel über einen Neustart hinweg. Man muss alle Host- und VM-Schlüssel nach einem Neustart erneut hinzufügen, sonst lässt sich eine solche VM nicht mehr starten.
Dies ist der Hauptvorteil des vCenters: Das Management des SKP (oder NKP) und der bereitgestellten Schlüssel für die ESXi-Hosts und VMs.
Als Workaround gibt es eine „automatische“ Sicherung der Verschlüsselungsschlüssel im Script. Das CSV-Backup wird bei der Generierung von Host- oder VM-Schlüsseln erstellt. Die Datei heißt tpm-keys.csv und sollte DRINGEND gut gesichert abgelegt werden Mit dieser Sicherungsdatei kann man alle Schlüssel (nach reboots) problemlos wieder auf den ESXi-Host importieren.
Wenn man über einen echten physischen TPM2.0 Chip verfügt (FIFO Modus, nicht CRB – bei HPE-Servern im BIOS umstellen!), kann man die „Schlüsselpersistenz“ im ESXi aktivieren. Damit werden die Schlüssel automatisch auf dem TPM-Chip gespeichert.
Wenn man keinen physischen TPM Chip hat, muss man sicherstellen, dass die Sicherungskopie der Host- und VM Schlüssel vorhanden ist. Nach dem Reboot kann man diese einfach wieder importieren. Man verbindet sich mit dem Host (siehe oben) und importiert die CSV wieder:
Den Erfolgt des Imports kann man jederzeit mit Get-VMHostTPMKeys kontrollieren.
🆘Hinweis zu Windows 11, wenn es nicht mehr bootet
Wenn eine Windows 11 VM nicht mehr neu starten sollte, weil man kein Backup der Schlüssel mehr hat:
VM aus der Bestandsliste entfernen (de-registrieren)
Die VMX Datei der VM manuell bearbeiten
Alle Zeilen, die mit dem vTPM zu tun haben löschen: vtpm.ekCSR vtpm.ekCRT vtpm.present encryption.keysafe encryption.data
Dann die VM (*.vmx) erneut zur Bestandsliste hinzufügen
Die VM hat dann zwar eine neue ID bekommen und muss (wahrscheinlich) erneut zur Datensicherungslösung hinzugefügt werden, bootet aber wieder problemlos.
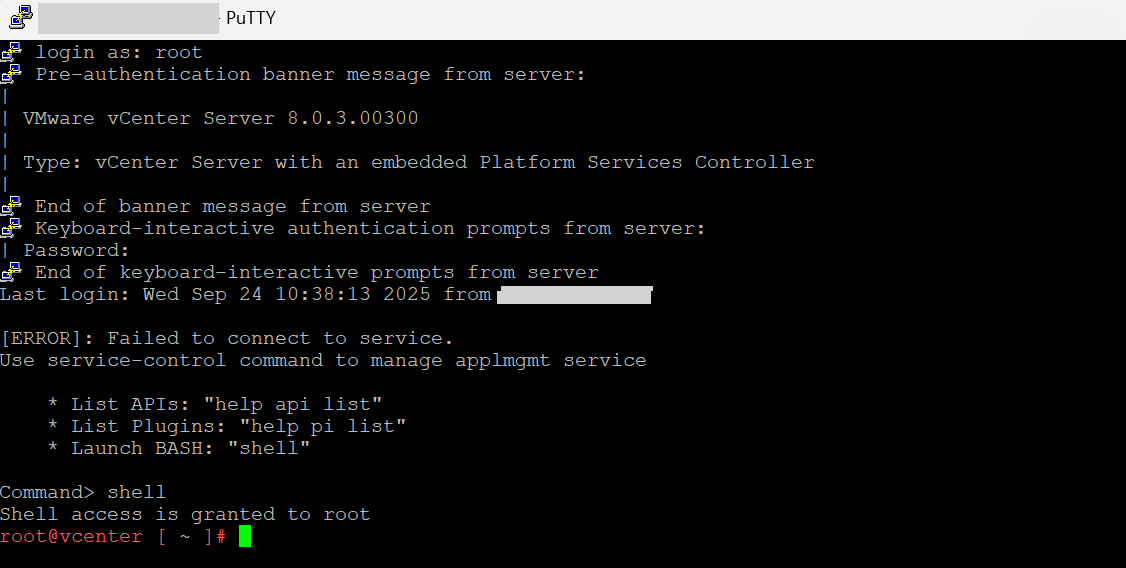
Nach einem Neustart meldet sich die VAMI (vCenter Appliance Management Interface) auf Port :5480 gerne mal mit der seltsamen Ausgaben 503 – OK.
Die Ursache von kennen wir nicht, aber angesichts der zahlreichen Java-Prozesse und der Java-Typischen Auslastung über längere Zeit, vermuten wir einen Timeout von einem der Servicecontroller.
Lösung
In der Regel ist der Application Management Controller (noch?) nicht gestartet. Das kann man an der shell aber schnell nachholen:
SSH auf den vCenter Server, als root -> Shell starten
2. Prüfen ob es der applmgmt ist:
service-control --status applmgmt
3. Wenn dieser „stopped“ ist, einfach wieder starten:
service-control --start applmgmt
… und nach wenigen Java-Minuten ist es soweit.
⚠️ Wir haben aber auch schon den Fall gesehen, dass applmgmt nicht starten wollte. Stattdessen erscheint die wenig hilfreiche Fehlermeldung „An error occurred while starting service ‚applmgmt'“. In unserem Fall haben dann mehrere vollstänige Neustarts der vCenter-VM geholfen, auf einmal waren die Dienste alle wieder da …
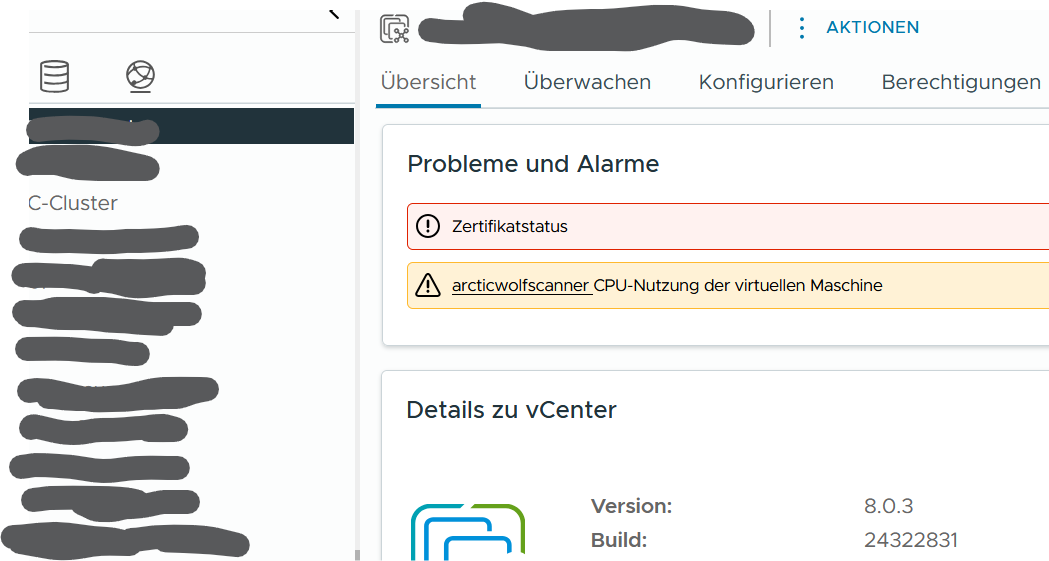
Manchmal begrüßt das vCenter den Admin mit einer eher rätselhaften „Zertifikatsstatus“ Fehlermeldung im vCenter UI. In diesem speziellen Fall war eine alte rootCA, die durch die Jahre der Datenmigration irgendwie noch vorhanden war. Es ist auch gar nicht so einfach, diese endlich loszuwerden.
Lösung
Zuerst muss man das betroffene Zertifikat finden. Es wäre natürlich viel zu hilfreich, wenn das UI das direkt anzeigen würde, daher muss man etwas tiefer gehen.
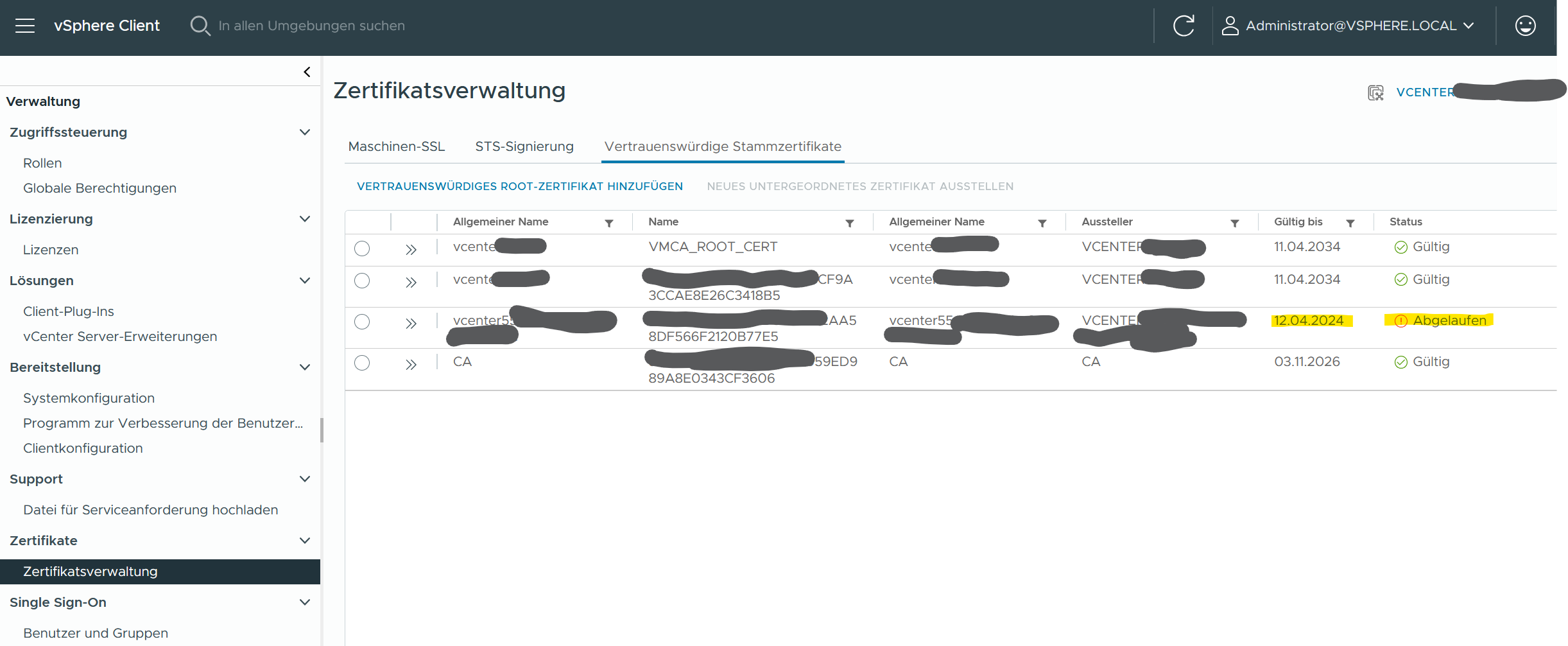
Die erste Anlaufstelle dazu ist der Zertifikatsmanager im vCenter unter Einstellungen > Verwaltung > Zertifikatsverwaltung. In diesem Fall hatten wir Glück, das abgelaufene „Vertrauenswürdige Stammzertifizierungsstellen“ Zertifikat war in der Liste enthalten. Das ist aber nicht immer der Fall, davon nicht entmutigen lassen.
Sollte das nicht funktionieren, kann man sich alle Zertifikate des vCenter Stores mit diesem Einzeiler an der Shell anzeigen lassen:
for i in $(/usr/lib/vmware-vmafd/bin/vecs-cli store list); do echo STORE $i; /usr/lib/vmware-vmafd/bin/vecs-cli entry list --store $i --text | egrep "Alias|Not After"; done
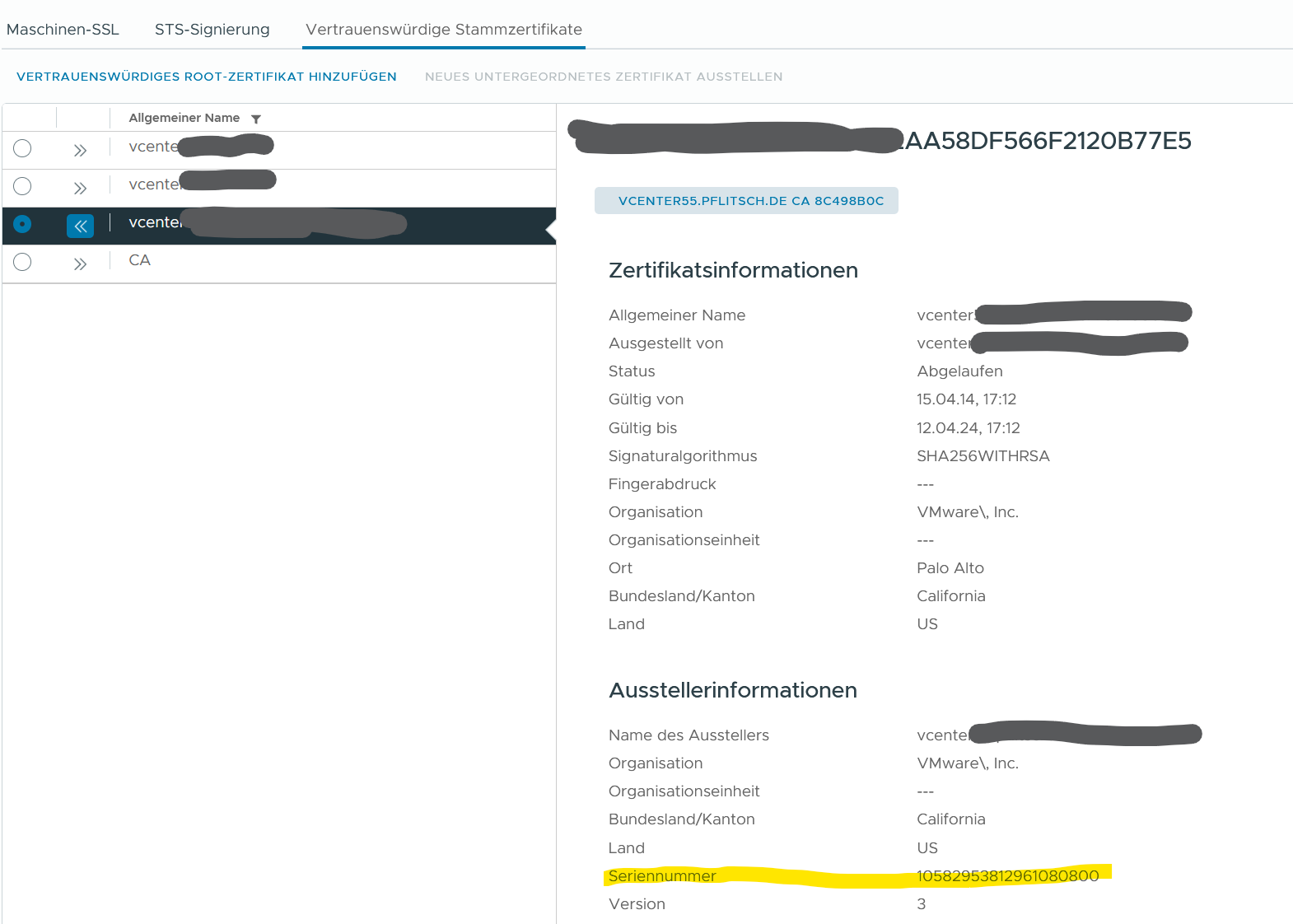
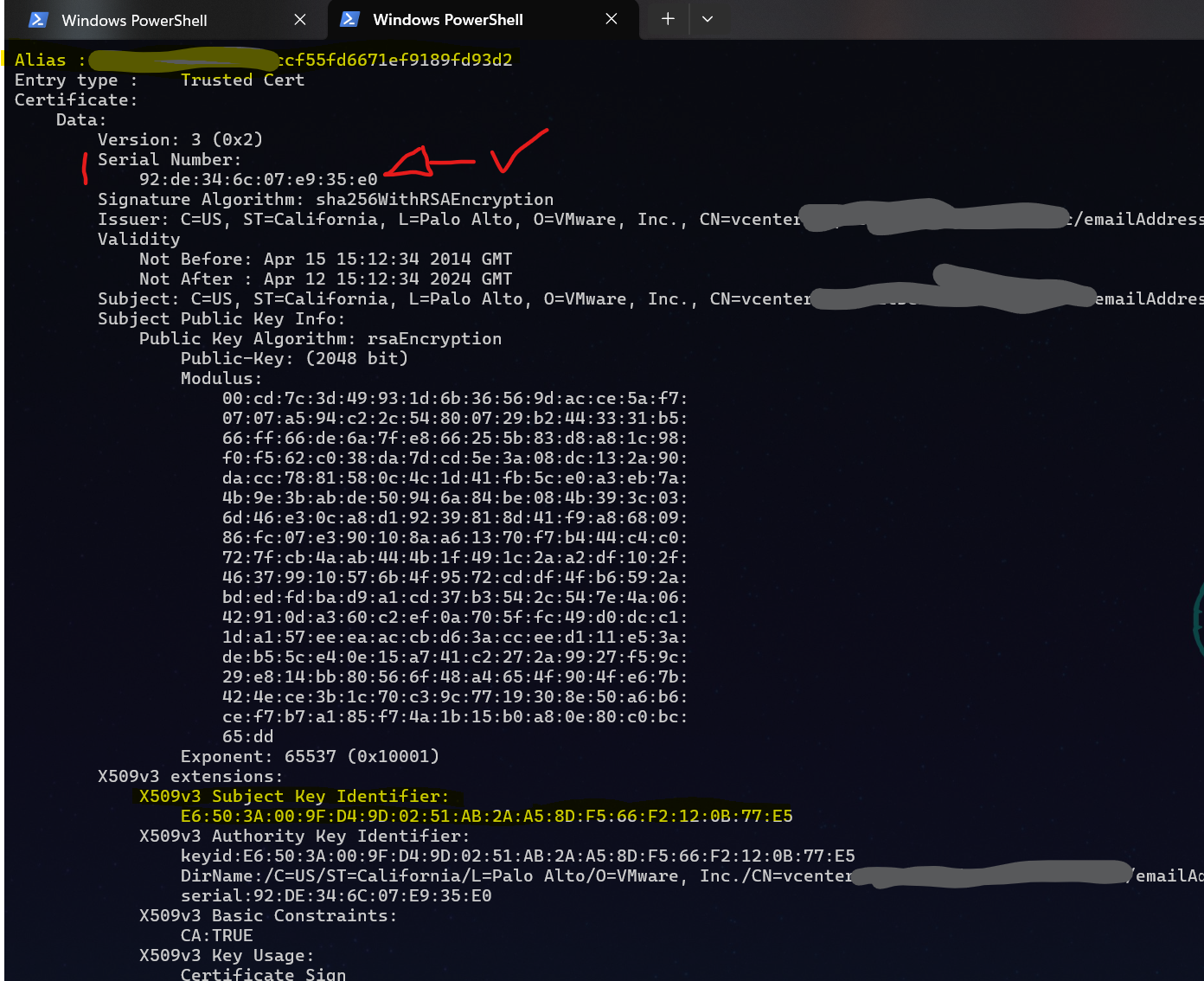
Im zweiten Schritt holen wir uns die (dezimale) Seriennummer des Zertifikates. Die UI zeigt die Nummer an, wenn man das betroffene Zertifikat auseinanderfaltet. Selbige Seriennummer rechnen wir schnell in hexadezimal um, weil alle anderen Tools die Seriennummer nur als hex-Wert angeben (*seufz*).
Also in diesem Fall:
10582953812961080800 = 92:DE:34:6C:07:E9:35:E0
Mit der Seriennummer bewaffnet, können wir uns an der Shell die „echten“ Zertifikatsdetails heraussuchen. Die Liste der Zertifikate bekommt man mit („q“ um less zu beenden):
/usr/lib/vmware-vmafd/bin/vecs-cli entry list --store TRUSTED_ROOTS --text | less
ℹ️ Es können auch mehrere Zertifikate entfernt werden. Alle abgelaufenen (und nicht verwendeten) Zertifikate sollten sogar entfernt werden, um diese zertifikatsbezogenen Alarme zu entfernen.
Aus dieser Liste brauchen wir eigentlich nur Alias und den X509v3 Subject Key Identifier:
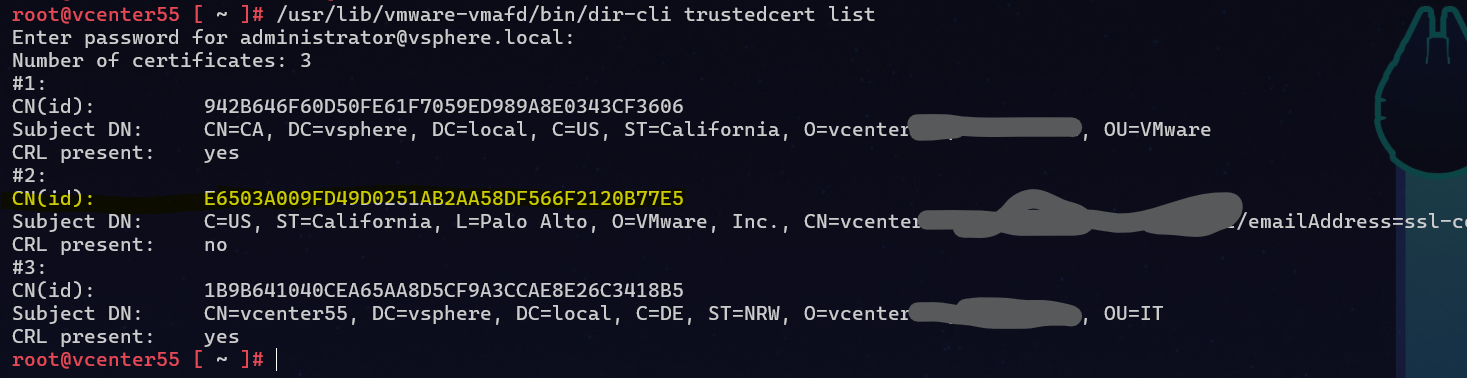
Jetzt brauchen wir von diesem Zertifikat wiederum den Thumbprint (vmware nennt das die „CN(id)“). Man nehme also nun den Fingerabdruck von dem CN, der abgelaufen gewesen ist. Die Fingerabdrücke listet man auf mit:
/usr/lib/vmware-vmafd/bin/dir-cli trustedcert list
Mit dem Thumbprint kann man nun endlich das Zertifikates exportieren und möglicherweise sogar ein Backup wegspeichern. Sicher ist sicher.
/usr/lib/vmware-vmafd/bin/dir-cli trustedcert get --id <THUMBPRINT> --login [email protected] --outcert /tmp/ABGELAUFENES-CERT.cer
Die Meldung „Certificate retrieved successfully“ bestätigt, dass das geklappt hat.
Wenn der Export vorliegt, kann man nun endlich das Zertifikat „Un-Publishen“:
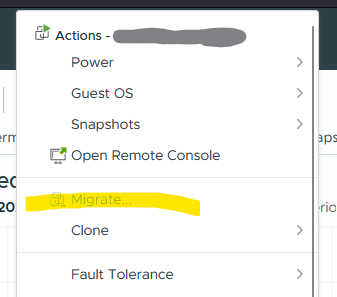
Manchmal kommt es vor, dass eine VM „überraschend“ nicht mehr migriert werden will. Die VM wurde aber schon mal migriert, vMotion ist lizenziert (meint: korrekt eingerichtet), andere VMs migrieren auch, nur diese eine hat die Option im Menü grau („ausgegraut„). Es laufen auch keine Jobs mehr, die die Migration verhindern können. Also keine andere (Storage/vmotion-) Migration, kein Backup oder andere Replikationsaufgaben.
Wie passiert das?
Das Problem kann auftreten, wenn eine Sicherungs- oder Storage-Motion-Vorgang einer VM zwar abgeschlossen ist, aber und die Einträge in der (PostgreSQL-) Tabelle aus dem vCenter Server nicht entfernt wurden. Das kann auch mal passieren, wenn Backup-Ende und vCenter-Reboot unglücklich zusammenfallen.
Wer das genau warum gewesen ist und wer noch betroffen ist, kann man in der Datenbank zum Glück schnell nachschauen. Auf der Shell des vCenter Servers gibt dieses Statement die entsprechende Liste für alle Objekte aus:
/opt/vmware/vpostgres/current/bin/psql -d VCDB -U postgres -c "select * from vpx_disabled_methods;"
Lösung
Wie bekommt man jetzt die Migrieren-Funktion zurück?
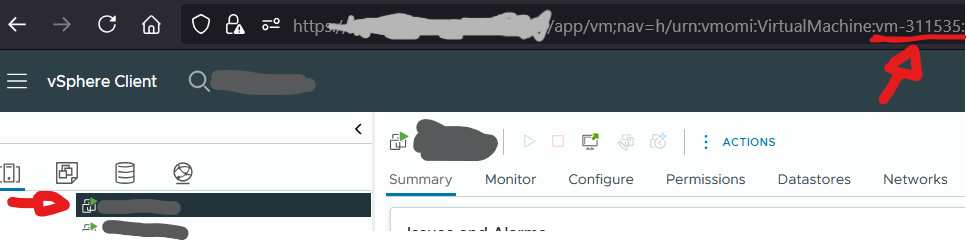
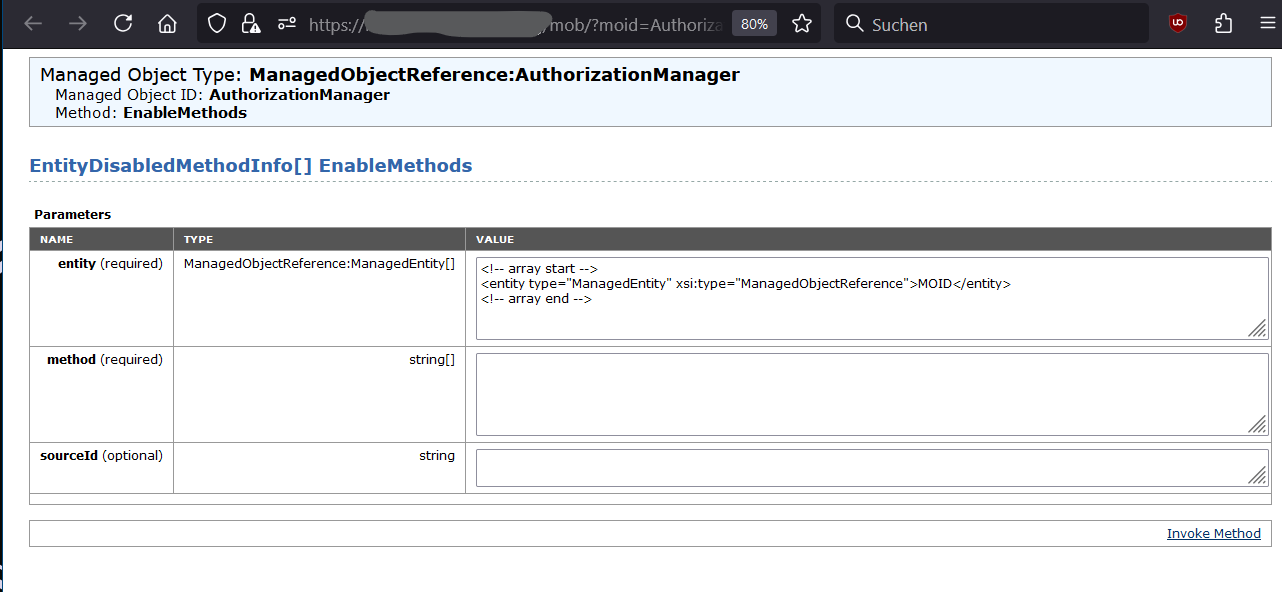
1. Man besorge sich die MO-ID („Managed Object“) ID der VM. Entweder aus dem MOB-Browser (https://VCENTER.EXAMPLE.COM/mob) oder direkt aus der URL vom vCenter GUI. Die URL enthält die MO-ID, wenn man im vCenter zu dem betreffenden Objekt navigiert und den Parameter „VirtualMachine:vm-1234568“ kopiert.
3. In selbigen fügt man oben („entity“) für „MOID“ die MO-ID (aus Schritt 1) ein und in der Mitte („method“) die Methode zum reversen des Feldes für „RelocateVM_Task“. Also genau dieses XML:
4. Unten rechts „Invoke Method“ führt die Methode aus und setzt die Felder zurück.
Der Erfolgsbericht folgt auch sofort, in maschinenlesbarer Form. Ein „Refresh“ im vCenter danach offenbart auch sofort die vermisste „Migrieren“ Funktion wieder.