Es ist zwar irgendwie nett zu wissen, das man mit den aktuellen Windows Updates nun endlich auch auf seinem Windows Server (und auf Windows Server Core) vernünftig mit seinem X-Box Live Account spielen kann, aber notwendig ist das für den Unternehmensbetrieb eher nicht.
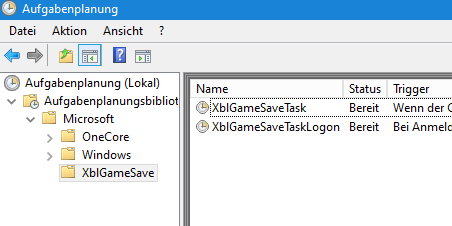
Wir wissen nicht was Microsoft dazu bewegt hat die Xbox „GameSaveTasks“ aus Server zu verteilen, zumal der Konzern selbst eher das genaue Gegenteil empfielt.
Lösung
Zum Glück kann man die entsprechenden Tasks schnell mit der PowerShell entfernen.
Hier ist die Copypasta:
Unregister-ScheduledTask -TaskName XblGameSaveTask -Confirm:$false
Unregister-ScheduledTask -TaskName XblGameSaveTaskLogon -Confirm:$false