Problem
Ein Programm bring einen Prozess mit, der immer laufen muss, wie ein Dienst. Leider hat der Programmierer die Dokumentation zu Windows-Services nicht gelesen (oder verstanden) und hat eine Desktop-Applikation gebaut. Jetzt muss der Server-Desktop immer angemeldet sein, damit der „Dienst“ läuft.
Das kommt (leider immer noch) in verschiedenen Fällen vor. Es gibt tatsächlich auch heute noch Unternehmen die glauben „einen viel besseren Webserver“ schreiben zu können oder eine Philosophie vertreten wie „Einen Webserver brauchen brauchen wir nicht, das kann die Software von selber“. Dieser technisch höchstkompetenten Ansage kann man als Admin weder mit Fakten noch Argumenten beikommen, für einige Programmierer existiert nur der Desktop und nichts weiter.
Lösung
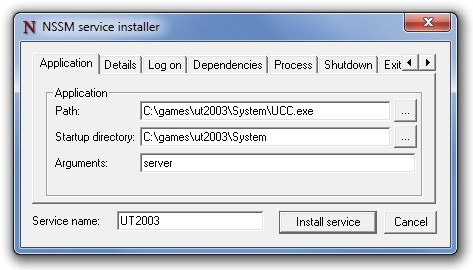
Admins to the rescue. Neben SRVANY, ServiceDemon und ähnlichen dreiviertelguten Ideen gibt es den NSSM – den „Non Sucking Service Manager“. Als eins der vermutlich besten Programme der aktuellen Windows-Admin Toolwelt kann der NSSM praktisch beliebige Programme als Dienst starten.
Das klappt ausgezeichnet mit Konsolenfenstern, Windows-Applikationen, Batchdateien, Datenbanken, Telekom-Telefonbüchern, Webbrowsern … praktisch allem. Das Tool kann auf einfachste Art dem Programm geben was es braucht (Logon-ID, Desktopsession, Pfade …) und stellt die Zwischenschischt zum Servicemanager dar. sogar Benutzerdefinierte Beendigungs-Parameter sind möglich, wie CTRL+C oder ALT+F4, bis hin zum einfachen Prozess beenden.