Problem
Bei der Installation von SLES 12 oder RHEL 7.4 tritt ein Blackscreen auf, die Installation geht nicht weiter.
Nach der Migration (oder Upload) von einem fertig installierten RHEL 7.4x gibt es nach dem einschalten einen Kernel-Dump und die Maschine bleibt stehen.
Lösung
Das passiert nur beim Einsatz der Intel E1000 Netzwerkkarte in der VM. Tauscht man die Karte gegen einen VMXNET-Adapter klappt alles. Wenn man den Kernel-Dump zerpflückt, sieht man im Call trace einen Reset der E1000 Karte.
Update: Nach unserem Case dazu hat vmware ein Update für den Host herausgebracht:
This issue is resolved in:
- ESXi 6.0 Update 1 and later, available at VMware Downloads.
- ESXi 5.5 Update 3b and later, available at VMware Downloads.

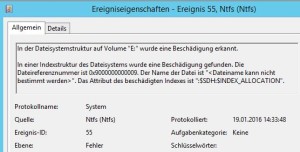 Das Erstellen eines oder mehrere Snapshots, zum Beispiel durch Backupsoftware (Veeam, R2Data, Tivoli …) erzeugt Fehler und Warnungen im Eventlog des Windows-Servers:
Das Erstellen eines oder mehrere Snapshots, zum Beispiel durch Backupsoftware (Veeam, R2Data, Tivoli …) erzeugt Fehler und Warnungen im Eventlog des Windows-Servers: