Problem
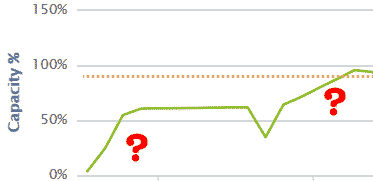 Eine SAN Lun (NetAPP, EMC, Nimble, Nutanix …) die (insgeheim oder nicht) Thin Provisioning auf dem Array (oder Volumen, Aggregat, Shelf, whateveritscalled) macht, läuft seit vSphere 5.x langsam voll. Es ist immer weniger Speicher auf dem Aggregat frei. Die Gastmaschienen bleiben gleich groß, aber jeder Storage-vMotion-Vorgang und jedes erstellen/löschen von Daten auf dem Datastore hinterlässt weniger freien phasikalischen Speicher auf dem Aggregat. Der Datastore wird im vSphere Client aber mit unverändert viel Speicher und unverändert viel freiem Speicher angezeigt. Nur die physikalisch Belegung wird größer und größer.
Eine SAN Lun (NetAPP, EMC, Nimble, Nutanix …) die (insgeheim oder nicht) Thin Provisioning auf dem Array (oder Volumen, Aggregat, Shelf, whateveritscalled) macht, läuft seit vSphere 5.x langsam voll. Es ist immer weniger Speicher auf dem Aggregat frei. Die Gastmaschienen bleiben gleich groß, aber jeder Storage-vMotion-Vorgang und jedes erstellen/löschen von Daten auf dem Datastore hinterlässt weniger freien phasikalischen Speicher auf dem Aggregat. Der Datastore wird im vSphere Client aber mit unverändert viel Speicher und unverändert viel freiem Speicher angezeigt. Nur die physikalisch Belegung wird größer und größer.
Lösung
Wenn eine thin provisioned Lun mit Daten beschrieben wird, werden diese Daten „hart“ geschrieben. Werden diese Daten dann wieder gelöscht, werden die Daten aber nicht wirklich gelöscht („mit Nullen überschrieben“), sondern die betroffenen Blöcke werden nur als „frei“ markiert. Ähnlich arbeiten praktisch alle heutigen Dateisysteme, weil ein Löschvorgang andernfall ein Schreibvorgang vollständiger größe und wäre und somit (potentiell) lange dauern würde.
Wenn nun häufig Daten geschrieben und gelöscht werden, werden nach und nach mehr Blöcke mit „als gelöscht“ markierten Daten hinterlassen. Ein SAN kann von aussen nicht unterscheiden, welche Daten echt sind und welche als löschbar markiert – dazu wäre technisch tiefe Einsicht in das Dateisystem notwendig. Tatsächlich freie Bereiche („Nullen“) erkennen SANs aber in der Regel als solche. Dieser Vorgang wird oft als punchzero, zero free space, reclaim wasted space, unmap disk space oder ähnliches bezeichnet.
Windows 2003 und höher
Unter Windows kann das Tool sDelete von Sysinternals den freien Bereich eines Datenträgers mit Nullen füllen.
c:\>sdelete -p 1 -z c:
ESX(i) Instalationen bringen ein entsprechendes Tool ebenfalls mit. Je nach vSphere Release unterscheidet gibt es allerdings etwas andere Namespaces dafür.
vSphere 5.1
vmkfstools -y 95 -d /vmfs/volumes/DATASTORENAME
vSphere 5.5
storage vmfs unmap -l DATASTORENAME
Linux
dd if=/dev/zero of=/DISK/foo.bar bs=4096 && rm -f /DISK/foo.bar
Zum Beispiel lässt sich dieser Vorgang auch via ESXCLI auslösen, zum Beispiel monatlich:
c:\>esxcli -s SERVER -u root -p PASSWD storage vmfs unmap -l DATASTORENAME