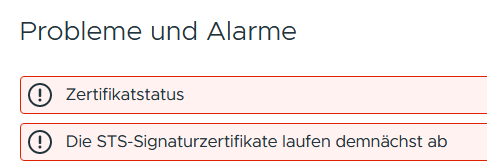
In der vCenter Server Appliance (VCSA) und/oder dem vSphere GUI wird diese Fehlermeldung angezeigt:
Die STS-Signaturzertifikate laufen demnächst abWenn man die VSCA rebootet, wird der Dienst vmware-vpxd nicht mehr gestartet. Jede erneute Anmeldung am vSphere-Client funktioniert mit diesem Fehler nicht mehr:
HTTP-Status 400 – Bad Request Message BadRequest
Signaturzertifikat ist ungültigIn /var/log/vmware/vpxd-svcs/vpxd-svcs.log gibt es Einträge wie diesen:
com.vmware.vim.sso.client.impl.SecurityTokenServiceImpl$RequestResponseProcessor opId=] Server rejected the provided time range. Cause:ns0:InvalidTimeRange: The token authority rejected an issue request for TimePeriodLösung
Dieses Problem tritt auf, wenn das Security Token Service (STS)-Zertifikat abgelaufen ist. Das führt dazu, dass interne Dienste keine gültigen Tokens mehr erwerben können und nicht mehr funktionieren. Wenn das STS-Zertifikat abläuft, geschieht das auch gerne mal ohne Vorwarnung (8.0.2.400+ fixt das wohl).
Es gibt von vmware einen guten Fix, der leider aktuell in der Broadcom-Umstellung nicht erreichbar ist. Hier ist der Mirror 🙂
- fixsts.sh (Hier als ZIP) herunterladen
- Auf der VCSA als
rootanmelden. Wenn das nicht mehr funktionieren sollte (Timeout und/oder Verbindungsabbruch), einfach als „[email protected]“ anmelden, die shell mitshell.set --enabled trueeinschalten und eine rootshell viasudo /bin/bashstarten. - Das Script
fixsts.shin /tmp ablegen und ausführbar machen:chmod +x /tmp/fixsts.sh - Das Script ausführen:
/tmp/fixsts.sh - Das Script generiert neue STS-Zertifikate und tauscht diese aus. Der Vergang braucht nicht lange. Danach muss man nur noch die vCenter Dienste neu starten:
service-control --stop --all && service-control --start --all