Aus Gründen musste ich heute eine VM ausfindig machen. Genauer musste eine VMWare Gastmaschine mit einer bestimmten IP und eine andere mit einer bestimmten MAC Adresse gefunden werden.
Im vCenter GUI (vSphere Client) geht das nicht, aber an der Powershell. Die MAC der (virtuellen) Netzwerkkarte kann man natürlich schon sehen, genau wie die IP-Adresse von Gastsystemen mit installieren VMWare-Tools. Aber man kann nach beidem nicht suchen.
Lösung
Mit dem VMWare PowerCLI (PowerShell) zum Host oder vCenter verbinden:
Connect-VIServer VCENTER.EXAMPLE.COMVMWare Gastsystem nach IP-Adresse suchen:
Get-VM | ? { $_.Guest.IPAddress -match "192.168.0.999" }VMWare Gastsystem nach MAC-Adresse suchen:
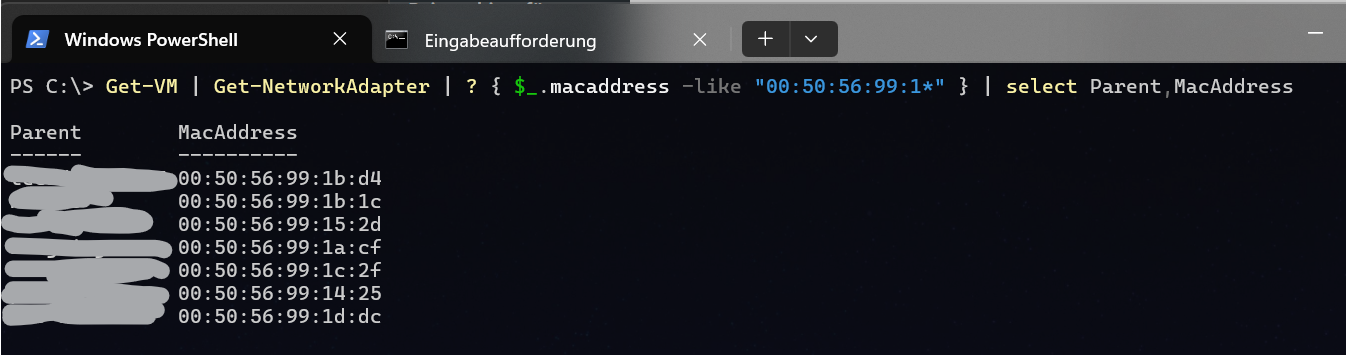
Get-VM | Get-NetworkAdapter | ? { $_.macaddress -like "00:50:56:99:1*" } | select Parent,MacAddressDas Format der MAC-Adressen in VMWare PowerCLI ist die Doppelpunkt-Trennung pro Byte „xx:xx:xx:xx:xx:xx“