Seit den aktuellsten Patchständen vom ESX5.1/5.5 an tritt dieser Pinkscreen-Fehler gehäuft auf:
@BlueScreen: #PF Exception 14 in world 63406:vmast.63405 IP 0x41801cd9c266 addr 0x0 PTEs:0x8442d5027;0x383f35027;0x0; Code start: 0x41801cc00000 VMK uptime: 1:08:27:56.829 0x41229eb9b590:[0x41801cd9c266]E1000PollRxRing@vmkernel#nover+0xdb9 stack: 0x410015264580 0x41229eb9b600:[0x41801cd9fc73]E1000DevRx@vmkernel#nover+0x18a stack: 0x41229eb9b630 0x41229eb9b6a0:[0x41801cd3ced0]IOChain_Resume@vmkernel#nover+0x247 stack: 0x41229eb9b6e0 0x41229eb9b6f0:[0x41801cd2c0e4]PortOutput@vmkernel#nover+0xe3 stack: 0x410012375940 0x41229eb9b750:[0x41801d1e476f]EtherswitchForwardLeafPortsQuick@#+0xd6 stack: 0x31200f9 0x41229eb9b950:[0x41801d1e5fd8]EtherswitchPortDispatch@#+0x13bb stack: 0x412200000015 0x41229eb9b9c0:[0x41801cd2b2c7]Port_InputResume@vmkernel#nover+0x146 stack: 0x412445c34cc0 0x41229eb9ba10:[0x41801cd2ca42]Port_Input_Committed@vmkernel#nover+0x29 stack: 0x41001203aa01 0x41229eb9ba70:[0x41801cd99a05]E1000DevAsyncTx@vmkernel#nover+0x190 stack: 0x41229eb9bab0 0x41229eb9bae0:[0x41801cd51813]NetWorldletPerVMCB@vmkernel#nover+0xae stack: 0x2 0x41229eb9bc60:[0x41801cd0b21b]WorldletProcessQueue@vmkernel#nover+0x486 stack: 0x41229eb9bd10 0x41229eb9bca0:[0x41801cd0b895]WorldletBHHandler@vmkernel#nover+0x60 stack: 0x10041229eb9bd20 0x41229eb9bd20:[0x41801cc2083a]BH_Check@vmkernel#nover+0x185 stack: 0x41229eb9be20 0x41229eb9be20:[0x41801cdbc9bc]CpuSchedIdleLoopInt@vmkernel#nover+0x13b stack: 0x29eb9bfa0 0x41229eb9bf10:[0x41801cdc4c1f]CpuSchedDispatch@vmkernel#nover+0xabe stack: 0x0 0x41229eb9bf80:[0x41801cdc5f4f]CpuSchedWait@vmkernel#nover+0x242 stack: 0x412200000000 0x41229eb9bfa0:[0x41801cdc659e]CpuSched_Wait@vmkernel#nover+0x1d stack: 0x41229eb9bff0 0x41229eb9bff0:[0x41801ccb1a3a]VmAssistantProcessTask@vmkernel#nover+0x445 stack: 0x0 0x41229eb9bff8:[0x0] stack: 0x0
Schuld sind Gast-VMs mit dem alten Intel e1000-Adapter darin. Wenn das Gast-Betriebssystem RSS (Receive Side Scaling) nutzt, was praktisch alle Windows-Versionen seit Vista tun, kann dieser Fehler sporadisch auftreten. Blöd ist natürlich, das der vmkernel das nicht verpackt und gleich den ganzen Host sterben lässt.
Lösung: Es gibt mehrere Möglichkeiten. Die sauberste und gesundeste ist, möglichst schnell alle e1000-Karten gegen das vmxnet-Pendant auszutauschen. eine Liste aller Gäste mit e1000-Karte bekommt man von der Shell auf einem Host mit:
root@labhost22# grep -s -i e1000 /vmfs/volumes/*/*/*.vmx
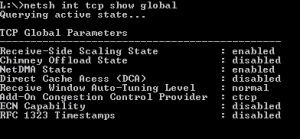 Die zweite und aus Performancesicht deutlich weniger schöne Möglichkeit ist, RSS in den Maschinen komplett auszuschalten. Ich hatte persönlich auch schon das Vergnügen mit Hosts, bei denen das TCPChimney auch ausgeschaltet werden musste, weil der Hosts sonst wieder nach 24 Stunden freundlich pink (purple) leuchtete.
Die zweite und aus Performancesicht deutlich weniger schöne Möglichkeit ist, RSS in den Maschinen komplett auszuschalten. Ich hatte persönlich auch schon das Vergnügen mit Hosts, bei denen das TCPChimney auch ausgeschaltet werden musste, weil der Hosts sonst wieder nach 24 Stunden freundlich pink (purple) leuchtete.
Unter Windows (ab 2008):
netsh int tcp set global rss=disabled
und
netsh int tcp set global chimney=disabled
Unter Linux muss man einen Blick in den geladenen Eth-Treiber werfen (modprobe klärt auf), denn RSS und TCP-Offloading sind da Treibersache. Natürlich ist jeder Treiber anders zu konfigurieren (der aus den VMTools kann auch vmxnet, wenn das also ein VM-Treiber ist, stellt einfach die Netzwerkkarte um).