
Grade in dieser Sekunde … HASS. 91 Minuten (!) HASS. Danke Microsoft, danke.
Monat: Januar 2016
Veeam: „Unable to release guest. Details: VSSControl: Failed to freeze guest, wait timeout“
Problem
Ab und zu werden Sicherungen in Veeam Backup and Replication mit dem Fehler „Unable to release guest. Details: VSSControl: Failed to freeze guest, wait timeout“ (Error: Mindestens ein Fehler ist aufgetreten.) abgeschlossen. Es tritt aber sonst kein Fehle auf, alle Snapshots werden korrekt zurückgerollt und die Sicherung ist auch intakt.
Lösung
Das Timeout von standarmäßig 900 Sekunden (15 Minuten) für das VSS-Freeze reicht je nach I/O Aktivität für manche Gäste nicht aus. Man kann das Timout aber problemlos (auf bis zu 30 Minuten) erhöhen. die Angabe in dem Schlüssel ist in Millisekunden.
HKEY_LOCAL_MACHINE\SOFTWARE\Wow6432Node\Veeam\Veeam Backup and Replication REG_DWORD (32bit): VssPreparationTimeout Wert: 1b7740 (hex, = 1800000 dec = 30 Minuten)
Für ältere 32bit-Systeme:
HKEY_LOCAL_MACHINE\SOFTWARE\Veeam\Veeam Backup and Replication REG_DWORD (32bit): VssPreparationTimeout Wert: 1b7740 (hex, = 1800000 dec = 30 Minuten)
Dann die Dienst(e) neu starten, fertig. Wenn das noch nicht ausreicht, gibt es offensichtlich irgendwo ein I/O-Problem; mehr als 30 Minuten für einen konsistenten Disk-State sind definitiv zu viel.
Zugehöriger Veeam-KB-Artikel: https://www.veeam.com/de/kb1377
vSphere erzeugt beim Snapshots-Erstellen NTFS-Fehler auf Windows-Servern (Event 50/57/137 …)
Problem
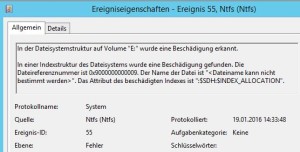 Das Erstellen eines oder mehrere Snapshots, zum Beispiel durch Backupsoftware (Veeam, R2Data, Tivoli …) erzeugt Fehler und Warnungen im Eventlog des Windows-Servers:
Das Erstellen eines oder mehrere Snapshots, zum Beispiel durch Backupsoftware (Veeam, R2Data, Tivoli …) erzeugt Fehler und Warnungen im Eventlog des Windows-Servers:
- ID 50 NTFS Warning, delayed write failed / delayed write lost
- ID 55 NTFS Fehler, In der Dateisystemstruktur wurde eine Fehler erkannt
- ID 57 NTFS Warning, failed to flush data to the transaction log. Courruption may occur.
- ID 137, NTFS Error, The default transaction resource manager on volume [] encountered a non-retryable error
- ID 140, NTFS Warning, failed to flush data to the transaction log. Courruption may occur in VolumeID:
- ID 12289 VSS Error, Volume Shadow Copy Service error: Unexpected error DeviceIOControl
Je nach Umstand können sogar echte Daten verloren gehen (unter Umständen sogar eine korrupte Datenbank). Die vmware-Version (vSphere 4/5/6, vRealize …) ist dabei irrelevant.
Lösung
Der Fehler liegt eigentlich am Windows Server und ist Microsoft bekannt (http://kb.vmware.com/kb/20068499). Eine Hotfix-Lösung gibt es leider (noch) nicht, aber bevor man mit defekten Daten hantiert und diese am Ende noch kaputt sichert, sollte man bei den betroffenen Systemen auf die quiescence verzichten:
- Config-Datei für die vmware Tools bearbeiten (oder erstellen, wenn nicht vorhanden)
C:\ProgramData\VMware\VMware Tools\Tools.conf
- Diese Zeilen einfügen:
[vmbackup] vss.disableAppQuiescing = true
- Dann den vmware Tools-Dienst neu starten
Und schon laufen externe Snapshots ohne Quiescence auf diesem System. Hoffentlich wird das bald gefixt …
CUPS meldet „Bad Request“ bei SSL auf IP/FQDN
Problem
Bei der Installation von CUPS (hier: 1.5.3) auf Debian gibt es ein unangenehmes Phänomen bei der Verwendung von ganzen Host- oder Domainnamen. Das CUPS-Webfrontend setzt standartmäßig bei einigen Operationen (Drucker ändern, Drucker löschen und so weiter) voraus, das die Seite via SSL geöffnet wird. Dazu wird auch ein Redirect-Link angezeigt. Klick man diesen, erscheint:
Bad Request
Passiert der Aufruf nicht über den im Zertifikat angegebenen CN, werfen erstens die großen Browser alle eine ’sec_error_untrusted_issuer‘ Meldung und zweitens das CUPS einen „Bad Request„. Dieser HTTP-Fehler 400 verwirrt, denn in der CUPS config ist der port korrekt eingetragen. Die Standardmäßige Wahl der Konfigurationsparameter ist hier etwas ungeschickt.
Lösung
Über die IP-Adresse (192.168.x.y:631) geht das Webfrontend auf, es sei denn das Zertifikat ist falsch. Der schnelle Admin erlaubt einfach alle eingehenden Anfragen.
- Korrektes, passendes Zertifikat für CUPS hinterlegen
openssl req -new -x509 -keyout /etc/cups/ssl/server.key -out /etc/cups/ssl/server.crt -days 3650 -nodes
(Hier dann dem Assistenten folgen, wichtig ist wie immer der „Common Name“ (CN))
- Konfigurationsdatei /etc/cups/cupsd.conf anpassen:
ServerAlias *
- Neustart der CUPS-Dienste
/etc/init.d/cups restart
Langes Passwort
Anruf von einem IT-Lieferanten (Zeiterfassung) eines Kunden:
Sicherheit ist ja sicher sehr wichtig, aber DAS HIER ist total übertrieben. So können wir nicht arbeiten, sorgen Sie SOFORT für einen EINFACHEN Zugang.
wtf? Was haben wir falsch gemacht?
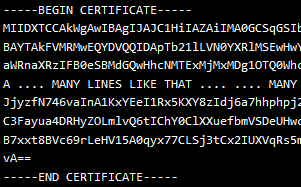 Stellt sich raus: Der zuständige Techniker des Lieferanten hat die Anleitung zum VPN nicht wirklich gelesen. Er hatte zwar die VPN-Verbindung (soweit korrekt) eingerichtet, aber anstatt des Kennwortes (das per Telefon übermittelt wurde), verwendete er das Zertifikat.
Stellt sich raus: Der zuständige Techniker des Lieferanten hat die Anleitung zum VPN nicht wirklich gelesen. Er hatte zwar die VPN-Verbindung (soweit korrekt) eingerichtet, aber anstatt des Kennwortes (das per Telefon übermittelt wurde), verwendete er das Zertifikat.
Den kompletten Text zwischen „—–BEGIN CERTIFICATE—–“ und „—–END CERTIFICATE—–“ aus der E-Mail gesendeten PEM-File. Er hat das ofenbar abgetippt. MEHRFACH. Nunja, bei einem x509-Zertifikat kommen da schon ein paar Zeichen zusammen … *kopfschüttel*